
ESTRUCTURA Y CÓDIGO DEL ADN http://youtu.be/RjyzsHXL3Ew
El ácido desoxirribonucleico, frecuentemente abreviado como ADN, es un ácido nucleico que contiene instrucciones genéticas usadas en el desarrollo y funcionamiento de todos los organismos vivos conocidos y algunos virus, y es responsable de su transmisión hereditaria. El papel principal de la molécula de ADN es el almacenamiento a largo plazo de información. Muchas veces, el ADN es comparado con un plano o una receta, o un código, ya que contiene las instrucciones necesarias para construir otros componentes de las células, como las proteínas y las moléculas de ARN. Los segmentos de ADN que llevan esta información genética son llamados genes, pero las otras secuencias de ADN tienen propósitos estructurales o toman parte en la regulación del uso de esta información genética.
 Desde el punto de vista químico, el ADN es un polímero de nucleótidos, es decir, un polinucleótido. Un polímero es un compuesto formado por muchas unidades simples conectadas entre sí, como si fuera un largo tren formado por vagones. En el ADN, cada vagón es un nucleótido, y cada nucleótido, a su vez, está formado por un azúcar (la desoxirribosa), una base nitrogenada (que puede ser adenina→A, timina→T, citosina→C o guanina→G) y un grupo fosfato que actúa como enganche de cada vagón con el siguiente.
Desde el punto de vista químico, el ADN es un polímero de nucleótidos, es decir, un polinucleótido. Un polímero es un compuesto formado por muchas unidades simples conectadas entre sí, como si fuera un largo tren formado por vagones. En el ADN, cada vagón es un nucleótido, y cada nucleótido, a su vez, está formado por un azúcar (la desoxirribosa), una base nitrogenada (que puede ser adenina→A, timina→T, citosina→C o guanina→G) y un grupo fosfato que actúa como enganche de cada vagón con el siguiente.  Lo que distingue a un vagón (nucleótido) de otro es, entonces, la base nitrogenada. Y por ello la secuencia del ADN se especifica nombrando sólo la secuencia de sus bases. La disposición secuencial de estas cuatro bases a lo largo de la cadena (el ordenamiento de los cuatro tipos de vagones a lo largo de todo el tren) es la que codifica la información genética. Por ejemplo, una secuencia de ADN puede ser ATGCTAGATCGC. En los organismos vivos, el ADN se presenta como una doble cadena de nucleótidos, en la que las dos hebras están unidas entre sí por unas conexiones denominadas puentes de hidrógeno. Para que la información que contiene el ADN pueda ser utilizada por la maquinaria celular, debe copiarse en primer lugar en unos trenes de nucleótidos, más cortos y con unas unidades diferentes, llamados ARN.
Lo que distingue a un vagón (nucleótido) de otro es, entonces, la base nitrogenada. Y por ello la secuencia del ADN se especifica nombrando sólo la secuencia de sus bases. La disposición secuencial de estas cuatro bases a lo largo de la cadena (el ordenamiento de los cuatro tipos de vagones a lo largo de todo el tren) es la que codifica la información genética. Por ejemplo, una secuencia de ADN puede ser ATGCTAGATCGC. En los organismos vivos, el ADN se presenta como una doble cadena de nucleótidos, en la que las dos hebras están unidas entre sí por unas conexiones denominadas puentes de hidrógeno. Para que la información que contiene el ADN pueda ser utilizada por la maquinaria celular, debe copiarse en primer lugar en unos trenes de nucleótidos, más cortos y con unas unidades diferentes, llamados ARN. 
Las moléculas de ARN se copian exactamente del ADN mediante un proceso denominado transcripción. Una vez procesadas en el núcleo celular, las moléculas de ARN pueden salir al citoplasma para su utilización posterior.
 La información contenida en el ARN se interpreta usando el código genético, que especifica la secuencia de los aminoácidos de las proteínas, según una correspondencia de un triplete de nucleótidos (codón) para cada aminoácido.
La información contenida en el ARN se interpreta usando el código genético, que especifica la secuencia de los aminoácidos de las proteínas, según una correspondencia de un triplete de nucleótidos (codón) para cada aminoácido.  Esto es, la información genética (esencialmente: qué proteínas se van a producir en cada momento del ciclo de vida de una célula) se halla codificada en las secuencias de nucleótidos del ADN y debe traducirse para poder funcionar. Tal traducción se realiza usando el código genético a modo de diccionario. El diccionario “secuencia de nucleótido-secuencia de aminoácidos” permite el ensamblado de largas cadenas de aminoácidos (las proteínas) en el citoplasma de la célula. Por ejemplo, en el caso de la secuencia de ADN indicada antes (ATGCTAGATCGC…), el ARN polimerasa utilizaría como molde la cadena complementaria de dicha secuencia de ADN (que sería TAC-GAT-CTA-GCG-…) para transcribir una molécula de ARN que se leería AUG-CUA-GAU-CGC-. El ARN resultante, utilizando el código genético, se traduciría como la secuencia de aminoácidos metionina-leucina-ácido aspártico-arginina-..
Esto es, la información genética (esencialmente: qué proteínas se van a producir en cada momento del ciclo de vida de una célula) se halla codificada en las secuencias de nucleótidos del ADN y debe traducirse para poder funcionar. Tal traducción se realiza usando el código genético a modo de diccionario. El diccionario “secuencia de nucleótido-secuencia de aminoácidos” permite el ensamblado de largas cadenas de aminoácidos (las proteínas) en el citoplasma de la célula. Por ejemplo, en el caso de la secuencia de ADN indicada antes (ATGCTAGATCGC…), el ARN polimerasa utilizaría como molde la cadena complementaria de dicha secuencia de ADN (que sería TAC-GAT-CTA-GCG-…) para transcribir una molécula de ARN que se leería AUG-CUA-GAU-CGC-. El ARN resultante, utilizando el código genético, se traduciría como la secuencia de aminoácidos metionina-leucina-ácido aspártico-arginina-..  Las secuencias de ADN que constituyen la unidad fundamental, física y funcional, de la herencia se denominan genes. Cada gen contiene una parte que se transcribe a ARN y otra que se encarga de definir cuándo y dónde deben expresarse. La información contenida en los genes (genética) se emplea para generar ARN y proteínas, que son los componentes básicos de las células, los “ladrillos” que se utilizan para la construcción de los orgánulos celulares, entre otras funciones. Dentro de las células, el ADN está organizado en estructuras llamadas cromosomas que, durante el ciclo celular, se duplican antes de que la célula se divida. Los organismos eucariotas (por ejemplo, animales, plantas, y hongos) almacenan la mayor parte de su ADN dentro del núcleo celular y una mínima parte en elementos celulares llamados mitocondrias, y en los plastos y los centros organizadores de microtúbulos o centríolos, en caso de tenerlos. Los organismos procariotas (bacterias y arqueas) lo almacenan en el citoplasma de la célula, y, por último, los virus ADN lo hacen en el interior de la cápsida de naturaleza proteica.
Las secuencias de ADN que constituyen la unidad fundamental, física y funcional, de la herencia se denominan genes. Cada gen contiene una parte que se transcribe a ARN y otra que se encarga de definir cuándo y dónde deben expresarse. La información contenida en los genes (genética) se emplea para generar ARN y proteínas, que son los componentes básicos de las células, los “ladrillos” que se utilizan para la construcción de los orgánulos celulares, entre otras funciones. Dentro de las células, el ADN está organizado en estructuras llamadas cromosomas que, durante el ciclo celular, se duplican antes de que la célula se divida. Los organismos eucariotas (por ejemplo, animales, plantas, y hongos) almacenan la mayor parte de su ADN dentro del núcleo celular y una mínima parte en elementos celulares llamados mitocondrias, y en los plastos y los centros organizadores de microtúbulos o centríolos, en caso de tenerlos. Los organismos procariotas (bacterias y arqueas) lo almacenan en el citoplasma de la célula, y, por último, los virus ADN lo hacen en el interior de la cápsida de naturaleza proteica.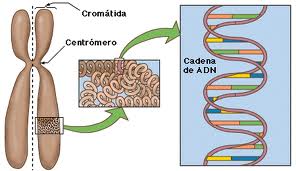



Fuente
HERENCIA Y CÓDIGO EPIGENÉTICO
No hay comentarios:
Publicar un comentario